
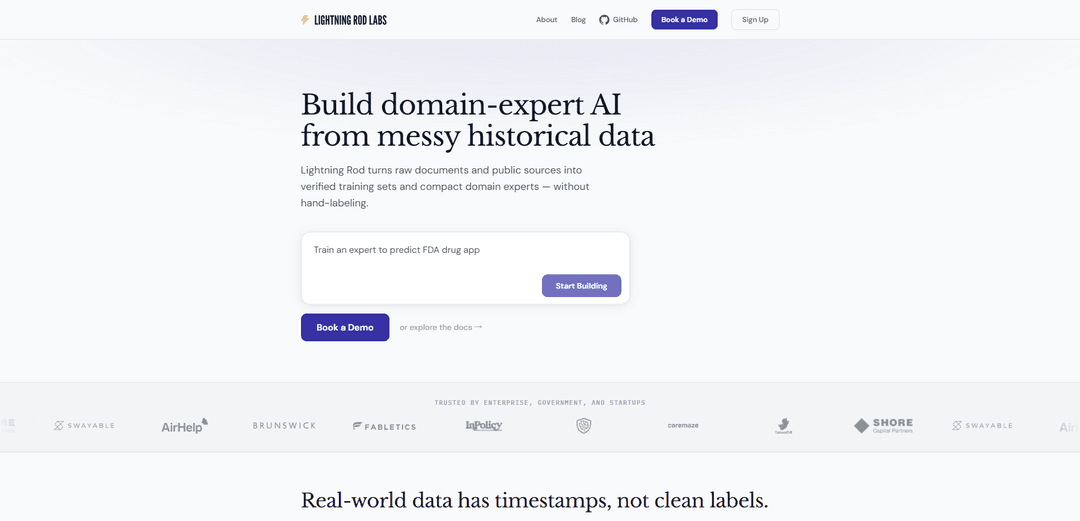
Lightning Rod: Generate training data
Lightning Rod ist eine KI-gestützte Lösung, die unstrukturierte Daten und öffentliche Quellen automatisch in hochwertige, verifizierte Trainingsdatensätze für den Aufbau von KI-Modellen mit Fachkenntnissen umwandelt, ohne manuelle Kennzeichnung.
https://www.lightningrod.ai/?ref=producthunt&utm_source=aipure
Produktinformationen
Aktualisiert:Apr 8, 2026
Was ist Lightning Rod: Generate training data
Lightning Rod ist eine umfassende Plattform, die Unternehmen dabei unterstützt, Trainingsdaten für KI-Modelle direkt aus realen Quellen wie Nachrichtenartikeln, Dokumenten und öffentlichen Feeds zu generieren. Es bietet ein einfaches Python-SDK, mit dem Entwickler schnell benutzerdefinierte Prognosedatensätze erstellen können, um Sprachmodelle (LLMs) zu trainieren. Die Plattform ist darauf spezialisiert, unordentliche, unstrukturierte Daten in saubere, gekennzeichnete Trainingsdatensätze umzuwandeln, die sofort für das Modelltraining und die -bewertung verwendet werden können.
Hauptfunktionen von Lightning Rod: Generate training data
Lightning Rod ist eine KI-gestützte Plattform, die automatisch hochwertige Trainingsdatensätze aus unstrukturierten historischen Daten ohne manuelle Kennzeichnung generiert. Sie verwendet eine \'Future-as-Label\'-Methodik, um Rohdokumente, Nachrichtenartikel und öffentliche Quellen in verifizierte Trainingssätze umzuwandeln, indem sie zeitliche Informationen und reale Ergebnisse nutzt, um beschriftete Daten für das KI-Modelltraining zu erstellen.
Automatisierte Datengenerierung: Transformiert Rohdokumente und unstrukturierte Daten in verifizierte Trainingsdatensätze unter Verwendung von zeitlichen Informationen und realen Ergebnissen, ohne dass eine manuelle Kennzeichnung erforderlich ist
Einfaches Python-SDK: Bietet eine einfach zu bedienende Python-API, die das Generieren benutzerdefinierter Datensätze in nur wenigen Codezeilen mit integrierten Pipeline-Komponenten für Datenerfassung, Fragengenerierung und Kennzeichnung ermöglicht
Quellenverifizierung: Stellt die Datenqualität sicher, indem alle generierten Trainingsbeispiele in abgerufenen Beweisen verankert werden und eine vollständige Provenienz mit Zitaten und Quelldokumenten bereitgestellt wird
Mehrere Datenquellen: Unterstützt sowohl öffentliche Datenquellen (Nachrichten, SEC-Einreichungen, Wikipedia) als auch private Dokumente (E-Mails, Tickets, Transkripte) als Eingabe für die Generierung von Trainingsdaten
Anwendungsfälle von Lightning Rod: Generate training data
Prognosemodelle: Trainieren von KI-Modellen zur Vorhersage zukünftiger Ereignisse und Ergebnisse anhand historischer Nachrichtendaten und realer Auflösungen
Finanzanalyse: Generieren von Trainingsdaten aus SEC-Einreichungen und Finanznachrichten, um Modelle für Marktvorhersagen und Investitionsanalysen zu erstellen
Richtlinienanalyse: Erstellen von Datensätzen über regulatorische Änderungen und politische Ergebnisse, um Modelle für die Vorhersage von politischen Auswirkungen zu trainieren
Kundenservice-KI: Konvertieren historischer Kundendienstinteraktionsprotokolle in Trainingsdaten für die Automatisierung des Kundendienstes
Vorteile
Reduziert den Zeit- und Arbeitsaufwand für die Erstellung von Datensätzen drastisch (von Wochen auf Stunden)
Gewährleistet eine hohe Datenqualität durch Verifizierung und Zitierung von Quellen
Flexible Integration mit öffentlichen und privaten Datenquellen
Einfache API, die minimalen Programmieraufwand erfordert
Nachteile
Erfordert API-Schlüssel und bezahlte Credits für die Nutzung
Kann durch die Verfügbarkeit und Qualität historischer Datenquellen eingeschränkt sein
Konzentriert sich derzeit hauptsächlich auf Prognose- und Zeitdatennutzungsfälle
Wie verwendet man Lightning Rod: Generate training data
Anmelden und API-Schlüssel erhalten: Melden Sie sich unter dashboard.lightningrod.ai an, um Ihren API-Schlüssel und 50 $ an kostenlosen Credits zu erhalten
Das SDK installieren: Installieren Sie das Lightning Rod Python SDK-Paket mit pip install lightningrod_ai
Erforderliche Module importieren: Importieren Sie die erforderlichen Klassen aus dem Lightningrod-Paket, einschließlich Pipeline, NewsSeedGenerator, ForwardLookingQuestionGenerator und WebSearchLabeler
Lightning Rod-Client initialisieren: Erstellen Sie eine LightningRod-Client-Instanz mit Ihrem API-Schlüssel: client = LightningRod(api_key=\'your-api-key\')
Datenpipeline konfigurieren: Richten Sie Pipeline-Komponenten ein, einschließlich Seed-Generator (Datenquelle), Fragengenerator (mit Anweisungen) und Labeler mit dem gewünschten Antworttyp
Die Pipeline ausführen: Führen Sie pipeline.run() mit der gewünschten Anzahl von Stichproben aus, um den Trainingsdatensatz automatisch zu generieren
Gekennzeichneten Datensatz erhalten: Greifen Sie auf den generierten Datensatz zu, der Fragen, Antworten, Konfidenzwerte und Quellenzitate enthält, die für das Modelltraining bereit sind
Lightning Rod: Generate training data FAQs
Lightning Rod ist eine Plattform, die Rohdokumente und öffentliche Quellen ohne manuelle Kennzeichnung in verifizierte Trainingsdatensätze und kompakte Domänenexperten umwandelt. Es verwendet eine Future-as-Label-Methodik, um qualitativ hochwertige Trainingsdaten aus realen Ergebnissen zu generieren.
Beliebte Artikel

Atoms: Eine Multi-Agenten-KI-Plattform, die Ideen in startbereite Produkte verwandelt
May 22, 2026

Nano Banana SBTI: Was es ist, wie es funktioniert und wie man es im Jahr 2026 einsetzt
Apr 15, 2026

Atoms Review – Der KI-Produkt-Builder, der die digitale Erstellung im Jahr 2026 neu definiert
Apr 10, 2026

Kilo Claw: Wie man einen echten "Do-It-For-You" KI-Agenten bereitstellt und verwendet (2026 Update)
Apr 3, 2026
Neueste KI-Tools ähnlich wie Lightning Rod: Generate training data

Tomat
Tomat.AI ist eine KI-gestützte Desktop-Anwendung, die es Benutzern ermöglicht, große CSV- und Excel-Dateien einfach zu erkunden, zu analysieren und zu automatisieren, ohne zu programmieren, und die lokale Verarbeitung sowie fortgeschrittene Datenmanipulationsfunktionen bietet.

Data Nuts
DataNuts ist ein umfassender Anbieter von Datenmanagement- und Analyselösungen, der sich auf Gesundheitslösungen, Cloud-Migration und KI-gestützte Datenbankabfragefähigkeiten spezialisiert hat.

CogniKeep AI
CogniKeep AI ist eine private, unternehmensgerechte KI-Lösung, die es Organisationen ermöglicht, sichere, anpassbare KI-Funktionen innerhalb ihrer eigenen Infrastruktur bereitzustellen und dabei vollständige Datenprivatsphäre und -sicherheit zu gewährleisten.

EasyRFP
EasyRFP ist ein KI-gestütztes Edge-Computing-Toolkit, das RFP (Request for Proposal)-Antworten optimiert und eine Echtzeit-Feldphänotypisierung durch Deep-Learning-Technologie ermöglicht.
Beliebte KI-Tools wie Lightning Rod: Generate training data

Researcher & Analyst in M365 Copilot
Contact for PricingAI Data Mining
Researcher und Analyst sind zwei neuartige KI-Reasoning-Agenten in Microsoft 365 Copilot, die Benutzern helfen, komplexe Forschungs- und Datenanalyseaufgaben zu bewältigen, indem sie sowohl Unternehmens- als auch Webdaten mit fortschrittlichen Reasoning-Funktionen nutzen.

ContextGem
ContextGem ist ein kostenloses Open-Source-LLM-Framework, das die Extraktion strukturierter Daten und Erkenntnisse aus Dokumenten mit minimalem Code durch leistungsstarke integrierte Abstraktionen und automatisierte Funktionen vereinfacht.

Augmentoolkit 3.0
Augmentoolkit 3.0 ist ein verfeinertes und praxiserprobtes Open-Source-Tool, das Domänenexperten-Datensätze erstellt, um benutzerdefinierte LLMs mit Ihren eigenen Daten zu trainieren. Es verfügt über eine intuitive Benutzeroberfläche, Offline-Funktionen sowie automatische Datensatzgenerierungs- und Trainingsprozesse.

OpenGyver
OpenGyver is an open-source Swiss-army-knife CLI tool with 47 commands and 180+ subcommands for everyday conversions, encoding, hashing, generation, formatting, and validation, designed for standalone use or integration with CI/CD pipelines, shell scripts, and AI agents.