
Query Memory
Query Memory ist eine einheitliche Workspace-Plattform, die das Parsen von Dokumenten, das Verwalten von Daten und das Bereitstellen von KI-Agenten über eine API-First-Architektur mit Funktionen für die Wissensindizierung, Agenten-Endpunkte und das Web-Parsing ermöglicht.
https://www.querymemory.com/?ref=producthunt&utm_source=aipure
Produktinformationen
Aktualisiert:Mar 16, 2026
Was ist Query Memory
Query Memory ist eine umfassende Plattform für die Dokumentenverarbeitung und KI-Agenten, die entwickelt wurde, um Entwicklern und Organisationen bei der Verarbeitung verschiedener Dokumenttypen und der Bereitstellung produktionsreifer KI-Workflows zu unterstützen. Sie bietet einen einheitlichen API-gesteuerten Arbeitsbereich, in dem Benutzer verschiedene Dokumentformate parsen, durchsuchbare Wissensdatenbanken erstellen, KI-Agenten konfigurieren und Web-Parsing-Funktionen implementieren können. Die Plattform dient als Brücke zwischen rohen Dokumentendaten und strukturierten, abfragbaren Informationen, die über KI-Agenten genutzt werden können.
Hauptfunktionen von Query Memory
Query Memory ist eine einheitliche Workspace-Plattform, die Dokumentenanalyse, Wissensindexierung und KI-Agenten-Bereitstellung über eine einzige API-First-Schnittstelle ermöglicht. Sie ermöglicht es Benutzern, verschiedene Dokumenttypen (PDF, DOCX, Tabellen, HTML, Bilder) zu verarbeiten, durchsuchbare Wissensdatenbanken zu erstellen und Produktions-Agenten-Workflows auszuführen, während sie einen hohen Durchsatz bei der Aufnahme, Indexierung und dem Abruf von gemischten Dokumenten- und Webdaten bieten.
Einheitliche Dokumentenverarbeitung: Analysieren und verarbeiten Sie mehrere Dokumentformate (PDF, DOCX, Tabellen, HTML, Bilder, Text) in strukturierte Elemente über eine einzige API-Schnittstelle
Wissensdatenbank-Verwaltung: Erstellen und verwalten Sie durchsuchbare Wissensdatenbanken aus indizierten Dokumenten mit schnellen semantischen Abruffunktionen
KI-Agenten-Konfiguration: Stellen Sie fundierte KI-Agenten mit Modellkontrollen, Prompts und quellenbewussten Antworten für automatisierte Workflows bereit und konfigurieren Sie sie
Web-Parsing-Integration: Führen Sie domänenspezifische Web-Extraktion und Rangfolge-Abruf für die Live-Erfassung externer Kontexte durch
Anwendungsfälle von Query Memory
Biotech-Forschungsanalyse: Verarbeiten und analysieren Sie Genomanalyse-Dokumente, klinische Pipeline-Notizen und Forschungsarbeiten über Wissensdatenbanken und spezialisierte Agenten
Dokumentenverwaltungssysteme: Erstellen Sie durchsuchbare Repositories aus gemischten Dokumenttypen mit semantischen Suchfunktionen für die unternehmensweite Dokumentenverwaltung
Automatisierte Datenextraktion: Extrahieren Sie strukturierte Informationen aus verschiedenen Dokumentformaten zur Datenverarbeitung und -analyse in Produktionsumgebungen
Vorteile
Hohe Leistung mit 90 % Durchsatz-Benchmark im Vergleich zu anderen Diensten
Einheitliche API-Schnittstelle für alle Dokumenttypen und -dienste
Skalierbares Preismodell vom kostenlosen Tarif bis zu Enterprise-Lösungen
Umfassende Analyse- und Nutzungsverfolgungsfunktionen
Nachteile
Eingeschränkte Funktionen im kostenlosen Tarif (nur 25 Dokumentenanalysen/Monat)
Erfordert möglicherweise technisches Fachwissen, um die API-Funktionen vollständig zu nutzen
Wie verwendet man Query Memory
Für ein Konto anmelden: Wählen Sie je nach Ihren Bedürfnissen zwischen dem Free-, Pro- oder Enterprise-Plan. Der Free-Plan beinhaltet 25 Dokumentenanalysen/Monat und grundlegende Funktionen für den Einstieg.
Dokumente hochladen: Laden Sie Ihre Dokumente (PDF, DOCX, Tabellen, HTML, Bilder, Text) in den Arbeitsbereich von Query Memory hoch, um sie zu parsen und zu indizieren.
Eine Wissensdatenbank erstellen: Richten Sie eine Wissensdatenbank ein, um Ihre hochgeladenen Dokumente für die semantische Suche und den Abruf zu organisieren und zu indizieren.
API-Zugriff konfigurieren: Holen Sie sich Ihren API-Schlüssel vom Dashboard, um mit dem Aufrufen von APIs zu beginnen. API-Schlüssel können im Abschnitt API-Schlüssel verwaltet und überwacht werden.
Dokumente über API abfragen: Verwenden Sie den REST-API-Endpunkt POST /api/v1/knowledge/{knowledge_id}/query, um Informationen aus Ihren indizierten Dokumenten mithilfe von natürlichsprachlichen Abfragen zu suchen und abzurufen.
Agenten einrichten (optional): Konfigurieren Sie KI-Agenten mit spezifischen Wissensdatenbanken und Webzugriffsberechtigungen, um Dokumentenverarbeitungs-Workflows zu automatisieren.
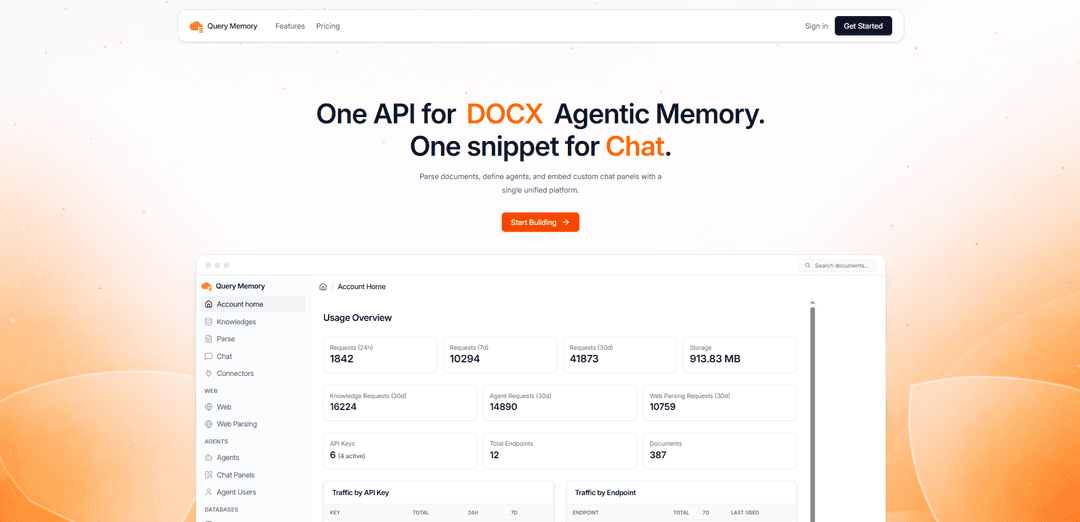
Nutzung überwachen: Verfolgen Sie Ihre Nutzungsmetriken, einschließlich Anfragen, Speicher und Endpunktverkehr, über das Dashboard Nutzungsübersicht.
Bei Bedarf skalieren: Überwachen Sie die Nutzung und aktualisieren Sie den Plan, wenn Ihre Anforderungen wachsen. Der Pro-Plan bietet 500 Dokumentenanalysen/Monat und der Enterprise-Plan bietet benutzerdefinierte Limits.
Query Memory FAQs
Query Memory ist eine einheitliche Workspace-Plattform, die es Benutzern ermöglicht, Dokumente zu parsen, Daten zu verwalten und KI-Agenten bereitzustellen. Sie bietet Dienste für Dokumentenparsing, Wissensindizierung, Agent-Endpunkte und Web-Parsing über einen einzigen API-First-Stack.
Beliebte Artikel

Atoms: Eine Multi-Agenten-KI-Plattform, die Ideen in startbereite Produkte verwandelt
May 22, 2026

Nano Banana SBTI: Was es ist, wie es funktioniert und wie man es im Jahr 2026 einsetzt
Apr 15, 2026

Atoms Review – Der KI-Produkt-Builder, der die digitale Erstellung im Jahr 2026 neu definiert
Apr 10, 2026

Kilo Claw: Wie man einen echten "Do-It-For-You" KI-Agenten bereitstellt und verwendet (2026 Update)
Apr 3, 2026
Neueste KI-Tools ähnlich wie Query Memory

Folderr
Folderr ist eine umfassende KI-Plattform, die es Nutzern ermöglicht, benutzerdefinierte KI-Assistenten zu erstellen, indem sie unbegrenzt Dateien hochladen, sich mit mehreren Sprachmodellen integrieren und Arbeitsabläufe über eine benutzerfreundliche Oberfläche automatisieren.

InDesign Translator
InDesign Translator ist ein Online-Übersetzungsdienst, der es Benutzern ermöglicht, InDesign-Dateien zu übersetzen, während Formatierungen und Stile beibehalten werden. Er bietet KI-unterstützte Übersetzungen und einfache Funktionen zur Zusammenarbeit, ohne dass Übersetzer InDesign installiert haben müssen.

Specgen.ai
Specgen.ai ist eine KI-gestützte Plattform, die Unternehmen hilft, ihre Angebotsantworten zu optimieren, indem sie Ausschreibungsanforderungen automatisch analysiert und personalisierte Antworten generiert, während sie 100%ige Datenvertraulichkeit durch proprietäre KI-Modelle gewährleistet.

TurboDoc
TurboDoc ist eine KI-gestützte Rechnungsverarbeitungssoftware, die automatisch unstrukturierte Rechnungsdaten in organisierte, leicht lesbare strukturierte Daten umwandelt, durch Gmail-Integration und intelligente Dokumentenverarbeitung.
Beliebte KI-Tools wie Query Memory

R2R
R2R (Reason to Retrieve) ist ein fortschrittliches KI-Abrufsystem, das produktionsreife Retrieval-Augmented Generation (RAG)-Funktionen mit multimodaler Content-Aufnahme, hybrider Suche, Wissensgraphen und umfassendem Dokumentenmanagement über eine RESTful-API bietet.

Claude Folder Upload
Eine Chrome-Erweiterung, die es Benutzern ermöglicht, ganze Ordner zu Claude AI hochzuladen, während die Verzeichnisstrukturen und Dateibeziehungen intelligent bewahrt werden, mit intelligenten Filterfunktionen für irrelevante Dateien.

Web Clipper for NotebookLM
Web Clipper für NotebookLM ist eine Chrome-Erweiterung, die Webseiten, PDFs, YouTube-Inhalte, soziale Beiträge/Threads und sogar KI-Chat-Konversationen mit einem Klick direkt in Google NotebookLM speichert und leistungsstarke Export-, Synchronisierungs- und Notizbuchverwaltungs-Tools hinzufügt.

ReadHero
ReadHero ist eine umfassende Buchverfolgungs- und Notizen-App, die Lesern hilft, sich an mehr von dem zu erinnern und es zu behalten, was sie lesen, indem sie Fortschrittsverfolgung, Notizen und Buchverwaltung an einem Ort ermöglicht.