HyperLLM
HyperLLM scheint ein Projekt oder eine Plattform im Zusammenhang mit großen Sprachmodellen zu sein, aber es gibt unzureichende Informationen, um eine detaillierte Beschreibung seiner Funktionen oder Fähigkeiten zu liefern.
https://hyperllm.org/?utm_source=aipure
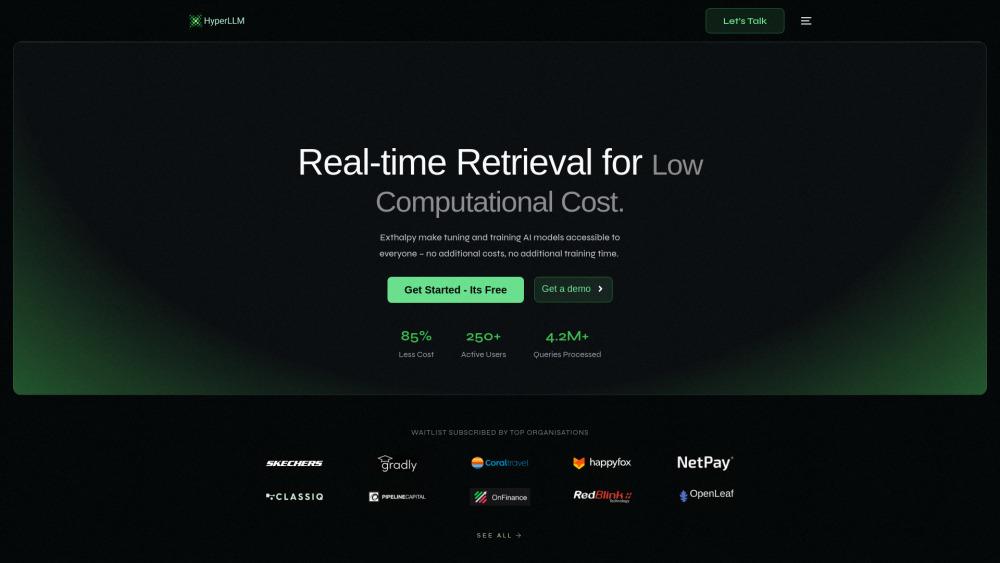
Produktinformationen
Aktualisiert:Nov 12, 2024
Was ist HyperLLM
HyperLLM scheint mit großen Sprachmodellen (LLMs) und künstlicher Intelligenz verbunden zu sein, basierend auf dem Domainnamen hyperllm.org. Die bereitgestellten Informationen enthalten jedoch keine spezifischen Details darüber, was HyperLLM ist oder was es tut. Die Website scheint zu existieren, enthält aber neben einer Copyright-Hinweis und Links zu Datenschutz- und Rechteseiten nur minimale Inhalte.
Hauptfunktionen von HyperLLM
HyperLLM ist eine Infrastrukturplattform, die entwickelt wurde, um die Entwicklung und den Einsatz von großen Sprachmodellen (LLMs) zu optimieren und zu vereinfachen. Sie umfasst Funktionen wie HyperCrawl für effizientes Web-Crawling, fortschrittliche Abrufmethoden und Tools für die Hyperparameter-Optimierung und das Experimentmanagement. HyperLLM zielt darauf ab, die Ressourcenanforderungen zu reduzieren und die Reproduzierbarkeit in der LLM-Forschung und den Anwendungen zu verbessern.
HyperCrawl: Ein Web-Crawler, der speziell für LLM- und RAG-Anwendungen entwickelt wurde und die Abrufprozesse verbessert, indem die Crawlzeit von Domains eliminiert wird.
Effiziente Verbindungsverwaltung: Reduziert Zeit und Ressourcen, indem bestehende Verbindungen wiederverwendet werden, anstatt neue zu öffnen.
Hyperparameter-Optimierungstools: Bietet Infrastruktur zum Speichern, Organisieren und Reproduzieren von maschinellem Lernen-Parametern und -Ergebnissen.
Experimentmanagement: Bietet Tools für Buchführung und Gewährleistung der Reproduzierbarkeit in schnell entwickelndem Forschungscode.
Anwendungsfälle von HyperLLM
LLM-Forschung: Ermöglicht Forschern die effiziente Entwicklung, Optimierung und Reproduktion von Experimenten mit großen Sprachmodellen.
Web-skalige Informationsabruf: Unterstützt den Aufbau leistungsstarker Abrufmaschinen für Anwendungen, die großflächige Webdaten erfordern.
Automatisierte Maschinelles Lernen (AutoML): Vereinfacht die Hyperparameter-Optimierung und Modellauswahl für Machine-Learning-Workflows.
Zusammenarbeit bei der KI-Entwicklung: Bietet Infrastruktur für Teams zur gemeinsamen Nutzung, Organisation und Diskussion von Experimenten, Daten und Algorithmen.
Vorteile
Verbessert die Effizienz in der LLM-Entwicklung und -Bereitstellung
Steigert die Reproduzierbarkeit von Machine-Learning-Experimenten
Optimiert Web-Crawling und Datenabruf für KI-Anwendungen
Nachteile
Erfordert möglicherweise erhebliche Einrichtungs- und Integrationsaufwände
Potenzielle Lernkurve für Teams, die die Plattform übernehmen
Wie verwendet man HyperLLM
Installiere HyperCrawl: HyperCrawl ist sowohl als API als auch als Python-Bibliothek verfügbar. Installiere die Python-Bibliothek, die Open-Source ist und kostenlos zu verwenden ist.
Importiere und initialisiere HyperCrawl: Importiere die HyperCrawl-Bibliothek in deinem Python-Projekt und initialisiere sie mit deinen gewünschten Konfigurationseinstellungen.
Setze Parallelität: Setze einen hohen Parallelitätswert, um dem Crawler zu ermöglichen, mehrere Aufgaben gleichzeitig zu bearbeiten, was den Prozess beschleunigt.
Definiere Crawl-Ziele: Gib die Websites oder Webseiten an, die du mit HyperCrawl crawlen und Daten von extrahieren möchtest.
Konfiguriere Extraktionsregeln: Definiere Regeln für die Art der Daten, die du von den gecrawlten Seiten extrahieren möchtest (z.B. Text, Links, Bilder).
Starte den Crawl: Initiiere den Crawl-Prozess mit Hilfe der HyperCrawl-API oder Bibliotheksfunktionen.
Verarbeite extrahierte Daten: Nach Abschluss des Crawlens verarbeite und analysiere die extrahierten Daten je nach deinem spezifischen Anwendungsfall.
Integriere mit LLM: Verwende die gecrawlten und verarbeiteten Daten als Eingabe für große Sprachmodelle (LLMs), um Erkenntnisse zu generieren oder andere NLP-Aufgaben durchzuführen.
HyperLLM FAQs
HyperCrawl ist der erste Webcrawler, der speziell für LLM- und RAG-Anwendungen entwickelt wurde. Es zielt darauf ab, den Abrufprozess zu beschleunigen, indem es die Crawlzeit von Domains eliminiert und fortschrittliche Methoden verwendet, um Abrufmaschinen zu erstellen.
Offizielle Beiträge
Wird geladen...Beliebte Artikel

Atoms: Eine Multi-Agenten-KI-Plattform, die Ideen in startbereite Produkte verwandelt
May 22, 2026

Nano Banana SBTI: Was es ist, wie es funktioniert und wie man es im Jahr 2026 einsetzt
Apr 15, 2026

Atoms Review – Der KI-Produkt-Builder, der die digitale Erstellung im Jahr 2026 neu definiert
Apr 10, 2026

Kilo Claw: Wie man einen echten "Do-It-For-You" KI-Agenten bereitstellt und verwendet (2026 Update)
Apr 3, 2026
Analyse der HyperLLM Website
HyperLLM Traffic & Rankings
0
Monatliche Besuche
-
Globaler Rang
-
Kategorie-Rang
Traffic-Trends: Jul 2024-Jun 2025
HyperLLM Nutzereinblicke
-
Durchschn. Besuchsdauer
0
Seiten pro Besuch
0%
Nutzer-Absprungrate
Top-Regionen von HyperLLM
Others: 100%
Neueste KI-Tools ähnlich wie HyperLLM

Athena AI
Athena AI ist eine vielseitige KI-gestützte Plattform, die personalisierte Studienhilfe, Geschäftslösungen und Lebensberatung durch Funktionen wie Dokumentenanalyse, Quizgenerierung, Karteikarten und interaktive Chat-Funktionen anbietet.

Aguru AI
Aguru AI ist eine On-Premises-Softwarelösung, die umfassende Überwachungs-, Sicherheits- und Optimierungstools für LLM-basierte Anwendungen mit Funktionen wie Verhaltensverfolgung, Anomalieerkennung und Leistungsoptimierung bietet.

GOAT AI
GOAT AI ist eine KI-gestützte Plattform, die Ein-Klick-Zusammenfassungsfunktionen für verschiedene Inhaltsarten, einschließlich Nachrichtenartikeln, Forschungsberichten und Videos, bietet und gleichzeitig fortschrittliche KI-Agentenorchestrierung für domänenspezifische Aufgaben anbietet.

GiGOS
GiGOS ist eine KI-Plattform, die Zugang zu mehreren fortschrittlichen Sprachmodellen wie Gemini, GPT-4, Claude und Grok mit einer intuitiven Benutzeroberfläche bietet, um mit verschiedenen KI-Modellen zu interagieren und diese zu vergleichen.
Beliebte KI-Tools wie HyperLLM

GPT‑5.5 | ChatGPT Official
GPT-5.5 in ChatGPT ist OpenAIs neuestes arbeitsorientiertes Modell, das entwickelt wurde, um komplexe Ziele zu verstehen, Tools effektiv zu nutzen, seine Arbeit zu überprüfen und mehrstufige Aufgaben (Codierung, Forschung, Dokumente, Tabellenkalkulationen) mit stärkeren Sicherheitsvorkehrungen bis zur Fertigstellung zu bearbeiten.

SearchGPT
SearchGPT ist ein KI-gestützter Suchprototyp von OpenAI, der schnelle, konversationelle Antworten mit klaren Quellen unter Verwendung von GPT-Modellen bietet.

ContextGem
ContextGem ist ein kostenloses Open-Source-LLM-Framework, das die Extraktion strukturierter Daten und Erkenntnisse aus Dokumenten mit minimalem Code durch leistungsstarke integrierte Abstraktionen und automatisierte Funktionen vereinfacht.

AI CLI
AI CLI ist ein Open-Source-Befehlszeilen-Interface-Tool, das KI-Funktionen direkt in Ihr Terminal bringt und es Ihnen ermöglicht, mit verschiedenen KI-Modellen wie OpenAIs GPT und Anthropic's Claude über einfache Befehle zu interagieren.