HyperLLM
HyperLLM parece ser um projeto ou plataforma relacionada a modelos de linguagem grandes, mas há informações insuficientes para fornecer uma descrição detalhada de suas características ou capacidades.
https://hyperllm.org/?utm_source=aipure
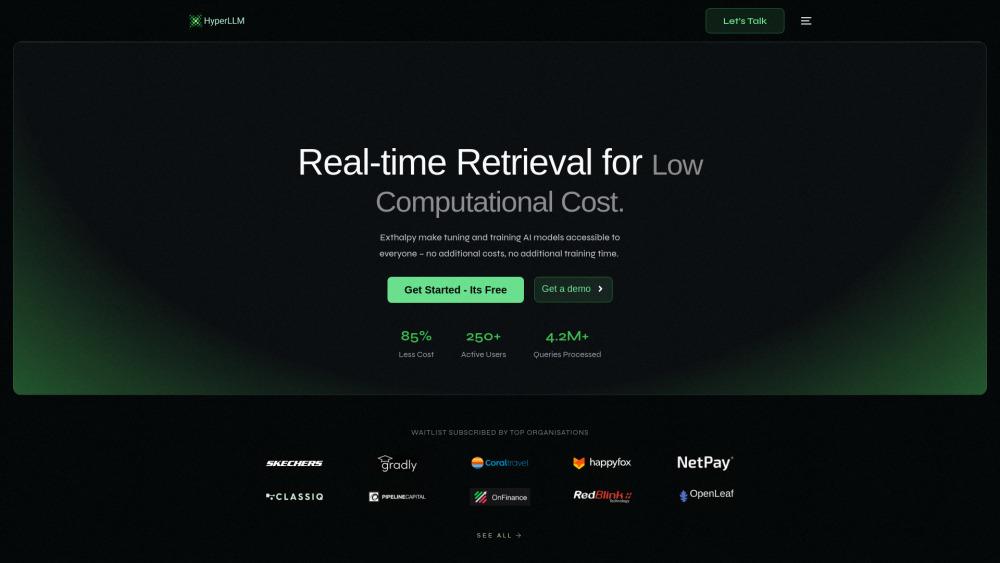
Informações do Produto
Atualizado:Nov 12, 2024
O que é HyperLLM
HyperLLM parece estar associado a modelos de linguagem grandes (LLMs) e inteligência artificial, com base no nome de domínio hyperllm.org. No entanto, as informações fornecidas não contêm detalhes específicos sobre o que é o HyperLLM ou o que ele faz. O site parece existir, mas tem conteúdo mínimo além de uma nota de direitos autorais e links para páginas de privacidade e legal.
Principais Recursos do HyperLLM
HyperLLM é uma plataforma de infraestrutura projetada para otimizar e agilizar o desenvolvimento e a implantação de grandes modelos de linguagem (LLMs). Inclui recursos como HyperCrawl para rastreamento eficiente na web, métodos avançados de recuperação e ferramentas para ajuste de hiperparâmetros e gerenciamento de experimentos. HyperLLM visa reduzir os requisitos de recursos e melhorar a reprodutibilidade na pesquisa e aplicações de LLMs.
HyperCrawl: Um rastreador na web especificamente projetado para aplicações de LLM e RAG, aumentando os processos de recuperação eliminando o tempo de rastreamento de domínios.
Gerenciamento Eficiente de Conexões: Reduz o tempo e os recursos necessários reutilizando conexões existentes em vez de abrir novas.
Ferramentas de Ajuste de Hiperparâmetros: Fornece infraestrutura para armazenar, organizar e reproduzir parâmetros e resultados de aprendizado de máquina.
Gerenciamento de Experimentos: Oferece ferramentas para contabilidade e garantia de reprodutibilidade em código de pesquisa em rápida evolução.
Casos de Uso do HyperLLM
Pesquisa de LLM: Permite que pesquisadores desenvolvam, ajustem e reproduzam experimentos com grandes modelos de linguagem de forma eficiente.
Recuperação de Informações em Escala na Web: Suporta a construção de potentes mecanismos de recuperação para aplicações que requerem dados web em larga escala.
Aprendizado de Máquina Automatizado (AutoML): Facilita a otimização de hiperparâmetros e a seleção de modelos para fluxos de trabalho de aprendizado de máquina.
Desenvolvimento Colaborativo de IA: Fornece infraestrutura para equipes compartilharem, organizarem e discutirem experimentos, dados e algoritmos.
Vantagens
Melhora a eficiência no desenvolvimento e implantação de LLMs
Aumenta a reprodutibilidade de experimentos de aprendizado de máquina
Agiliza o rastreamento na web e a recuperação de dados para aplicações de IA
Desvantagens
Pode exigir esforço significativo de configuração e integração
Curva de aprendizado potencial para equipes adotando a plataforma
Como Usar o HyperLLM
Instale o HyperCrawl: O HyperCrawl está disponível tanto como uma API quanto como uma biblioteca Python. Instale a biblioteca Python, que é de código aberto e gratuita para uso.
Importe e inicialize o HyperCrawl: Importe a biblioteca HyperCrawl em seu projeto Python e inicialize-a com as configurações desejadas.
Defina a concorrência: Defina um valor alto de concorrência para permitir que o crawler lide com múltiplas tarefas simultaneamente, o que acelera o processo.
Defina os alvos de rastreamento: Especifique os sites ou páginas da web que você deseja que o HyperCrawl rastreie e extraia dados.
Configure as regras de extração: Defina regras para o tipo de dados que você deseja extrair das páginas rastreadas (por exemplo, texto, links, imagens).
Inicie o rastreamento: Inicie o processo de rastreamento usando a API ou funções da biblioteca HyperCrawl.
Processar dados extraídos: Após a conclusão do rastreamento, processe e analise os dados extraídos conforme necessário para seu caso de uso específico.
Integre com LLM: Use os dados rastreados e processados como entrada para modelos de linguagem grandes (LLMs) para gerar insights ou realizar outras tarefas de NLP.
Perguntas Frequentes do HyperLLM
HyperCrawl é o primeiro web crawler projetado especificamente para aplicações LLM e RAG. Tem como objetivo aumentar o processo de recuperação eliminando o tempo de crawl de domínios e utiliza métodos avançados para construir motores de recuperação.
Postagens Oficiais
Carregando...Artigos Populares

Atoms: Uma Plataforma de IA Multiagente Que Transforma Ideias em Produtos Prontos para Lançamento
May 22, 2026

Nano Banana SBTI: O Que É, Como Funciona e Como Usá-lo em 2026
Apr 15, 2026

Análise do Atoms — O Construtor de Produtos de IA Redefinindo a Criação Digital em 2026
Apr 10, 2026

Kilo Claw: Como Implementar e Usar um Verdadeiro Agente de IA "Faça Você Mesmo" (Atualização de 2026)
Apr 3, 2026
Análises do Site HyperLLM
Tráfego e Classificações do HyperLLM
0
Visitas Mensais
-
Classificação Global
-
Classificação por Categoria
Tendências de Tráfego: Jul 2024-Jun 2025
Insights dos Usuários do HyperLLM
-
Duração Média da Visita
0
Páginas por Visita
0%
Taxa de Rejeição dos Usuários
Principais Regiões do HyperLLM
Others: 100%
Ferramentas de IA Mais Recentes Semelhantes a HyperLLM

Athena AI
O Athena AI é uma plataforma versátil alimentada por IA que oferece assistência de estudo personalizada, soluções de negócios e coaching de vida por meio de recursos como análise de documentos, geração de questionários, flashcards e capacidades de chat interativo.

Aguru AI
Aguru AI é uma solução de software local que fornece ferramentas abrangentes de monitoramento, segurança e otimização para aplicações baseadas em LLM, com recursos como rastreamento de comportamento, detecção de anomalias e otimização de desempenho.

GOAT AI
GOAT AI é uma plataforma alimentada por IA que fornece capacidades de resumo com um clique para vários tipos de conteúdo, incluindo artigos de notícias, trabalhos de pesquisa e vídeos, enquanto também oferece orquestração avançada de agentes de IA para tarefas específicas de domínio.

GiGOS
O GiGOS é uma plataforma de IA que fornece acesso a múltiplos modelos de linguagem avançados como Gemini, GPT-4, Claude e Grok com uma interface intuitiva para os usuários interagirem e compararem diferentes modelos de IA.
Ferramentas de IA Populares Como HyperLLM

GPT‑5.5 | ChatGPT Official
O GPT-5.5 no ChatGPT é o modelo mais recente da OpenAI focado no trabalho, projetado para entender objetivos complexos, usar ferramentas de forma eficaz, verificar seu trabalho e realizar tarefas de várias etapas (codificação, pesquisa, documentos, planilhas) até a conclusão com salvaguardas mais fortes.

SearchGPT
SearchGPT é um protótipo de busca alimentado por IA da OpenAI que fornece respostas rápidas e conversacionais com fontes claras usando modelos GPT.

ContextGem
ContextGem é uma estrutura LLM gratuita e de código aberto que simplifica a extração de dados estruturados e insights de documentos com código mínimo por meio de poderosas abstrações integradas e recursos automatizados.

AI CLI
AI CLI é uma ferramenta de interface de linha de comando de código aberto que traz recursos de IA diretamente para o seu terminal, permitindo que você interaja com vários modelos de IA, como GPT da OpenAI e Claude da Anthropic, por meio de comandos simples.